Aim
This collection captures information about the 2018 national elections in Luxembourg between 1st January 2018 to 1st January 2019.
Seed list
DownloadCoverage
Selective coverage on social media, with up to 6 captures for Facebook seeds and up to 60 captures for Twitter seeds.
Extensive coverage on election related websites and civil interests between 1 and 5 captures per seed.
Broad coverage on online news media with one capture per individual news article.
Foreign websites
Very few seeds outside the .lu domain.
No research on foreign websites.
What we captured
Capturing the elections
“Television is no gimmick, and nobody will ever be elected to major office again without presenting themselves well on it.” – Roger Ailes, 1968. Even though TV and print media still prevail in the Luxembourg political environment, the influence of online information is continually growing. The days when elections are either won or lost, based on the success of online campaigning may not be far away. Recently, Luxembourg has seen an exceptional time in political discourse, since the country held local elections in 2017 and national elections in 2018 (plus the European elections in 2019).
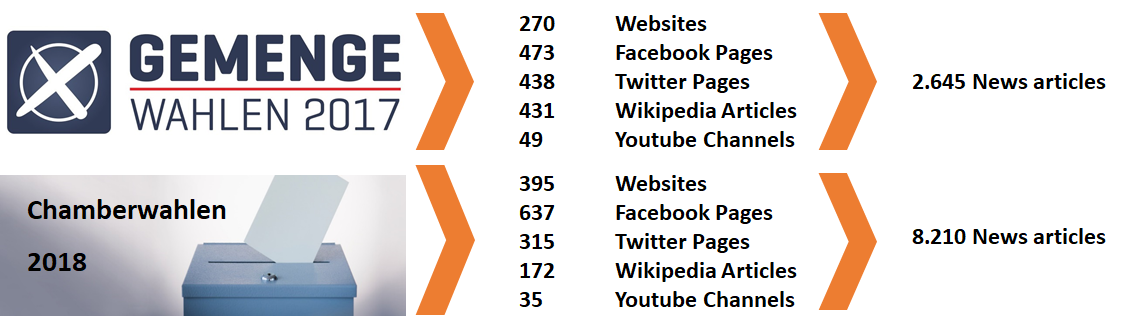
2 years of crawling
As a pilot project in targeted web crawls, the National Library of Luxembourg has archived over the course of two years: websites, social media profiles and online news media in relation with local and national election campaigns. While we were able to include Facebook and Twitter profiles of candidates and political parties, aiming at completeness in capturing all relevant content from social media was simply out of reach, due to technical hurdles and not being able to keep up with the pace of changing content.
News media tagging
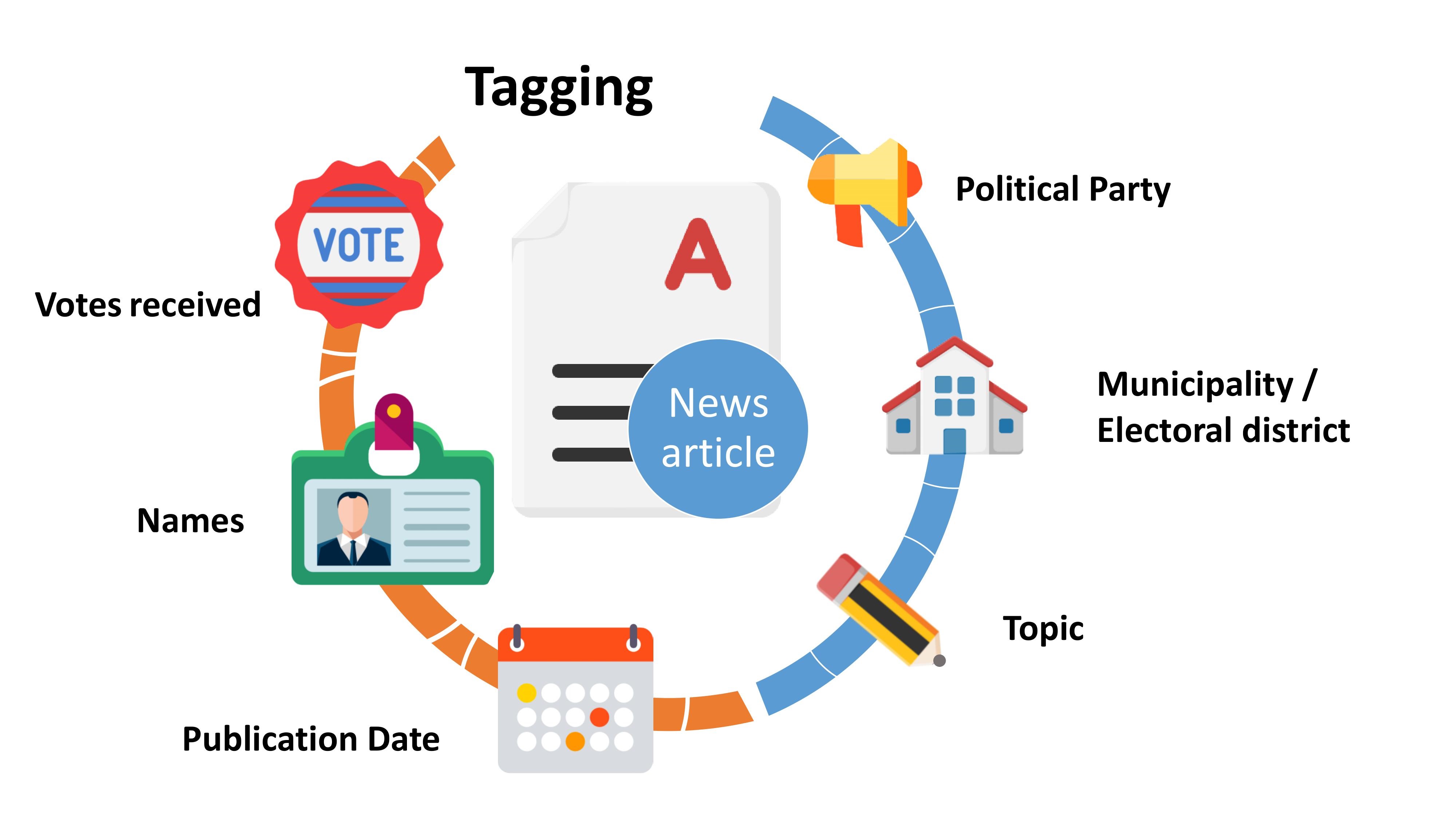
For this reason, a focal point of the project is the online news media collection. After searching the archives and different sub-categories of each news site, we decided to check each news site daily and add individual articles to the collection. This approach not only helps with keeping up with current discussions and trends, but also allows to track changes to the media landscape: several new sites emerged over the course of the project, others changed their structure, address, or disappeared completely. Handpicking individual articles, instead of archiving the entire website, is very time consuming, but cost-effective in data consumption and also very reliable in terms of harvest quality. Moreover, each article is saved as a separate object in the collection, allowing us to go one step further in our data analysis. We tagged each article in the fields illustrated to the right:
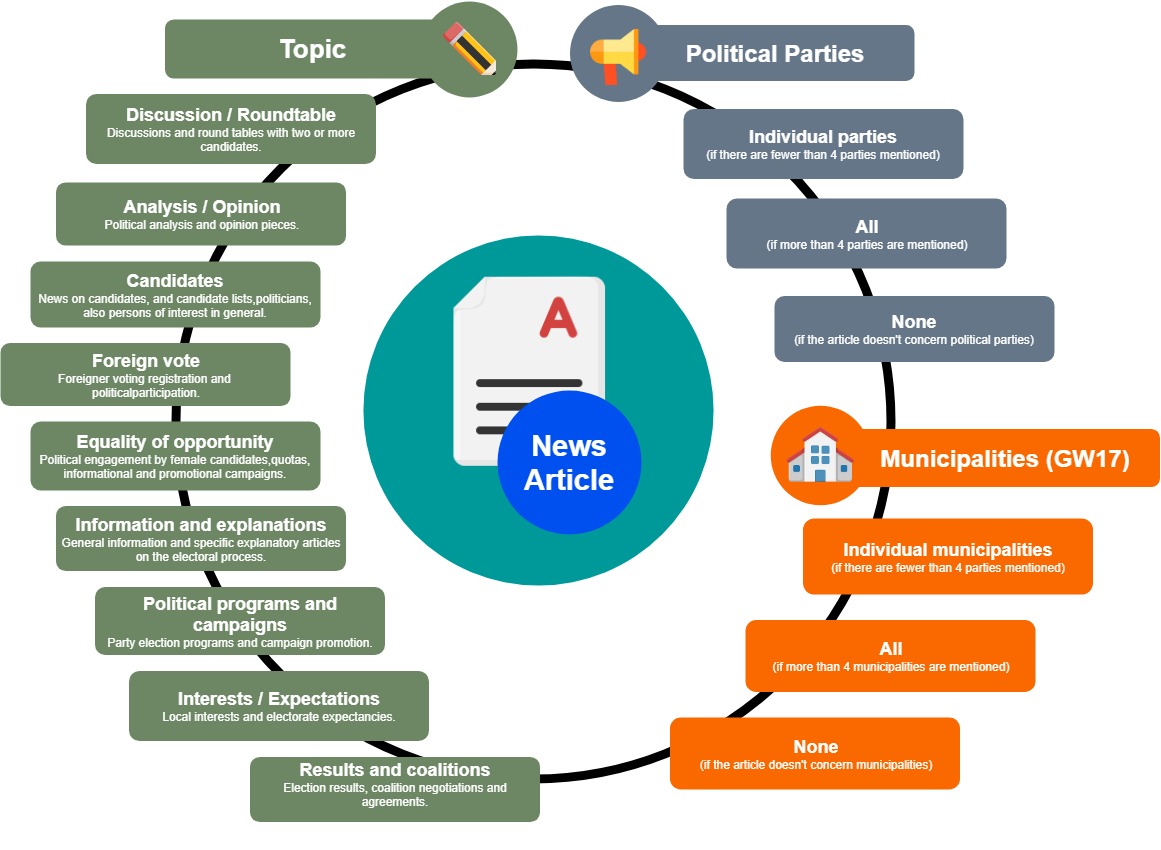
Fields and topics
Same as the article selection, this manual procedure was completed by one person, with a single screening of each article and its resulting characterisation is therefore subjective. In the context of the 2017 local elections, over 2600 news articles were harvested and tagged. News coverage of the 2018 national elections however produced over 8200 articles. While the “Topic” field was also tagged manually, we wanted to move on to automated tagging in the fields of “Political party”, “Electoral district”, “Publication date” and “Votes received”. The publication dates of articles were captured by a web scraping tool from the live web versions of the articles. By extracting the text fields from the archived WARC files, we would like to determine the names of political candidates mentioned in each article, as well as mentions of political parties and other regular expressions (such as nicknames or official titles for example). By determining the mentions of political parties and candidates, the electoral district can be deduced automatically. Since the results of the elections are in, the number of votes received for each candidate, or party mentioned in the article, can also be attributed to a field.
Analysis and visualisation
Filling out each field, allows for a variety of possible dissections: which news site published most articles on a certain subject, or which municipality was most often linked with a certain political party. You could find out which candidate had the highest number of mentions a certain date, or compare the number of mentions with the number of votes received. We could create a publication timeline, or geographic heat map for any combination of fields. To create and visualise these queries, we use Kibana, a data search engine and analysis tool. From a customisable dashboard, we can explore different constellations of news articles we are interested in. For example, we can find out which party’s candidates had the most media coverage in Luxembourg City and know the URLs of the respective articles are.
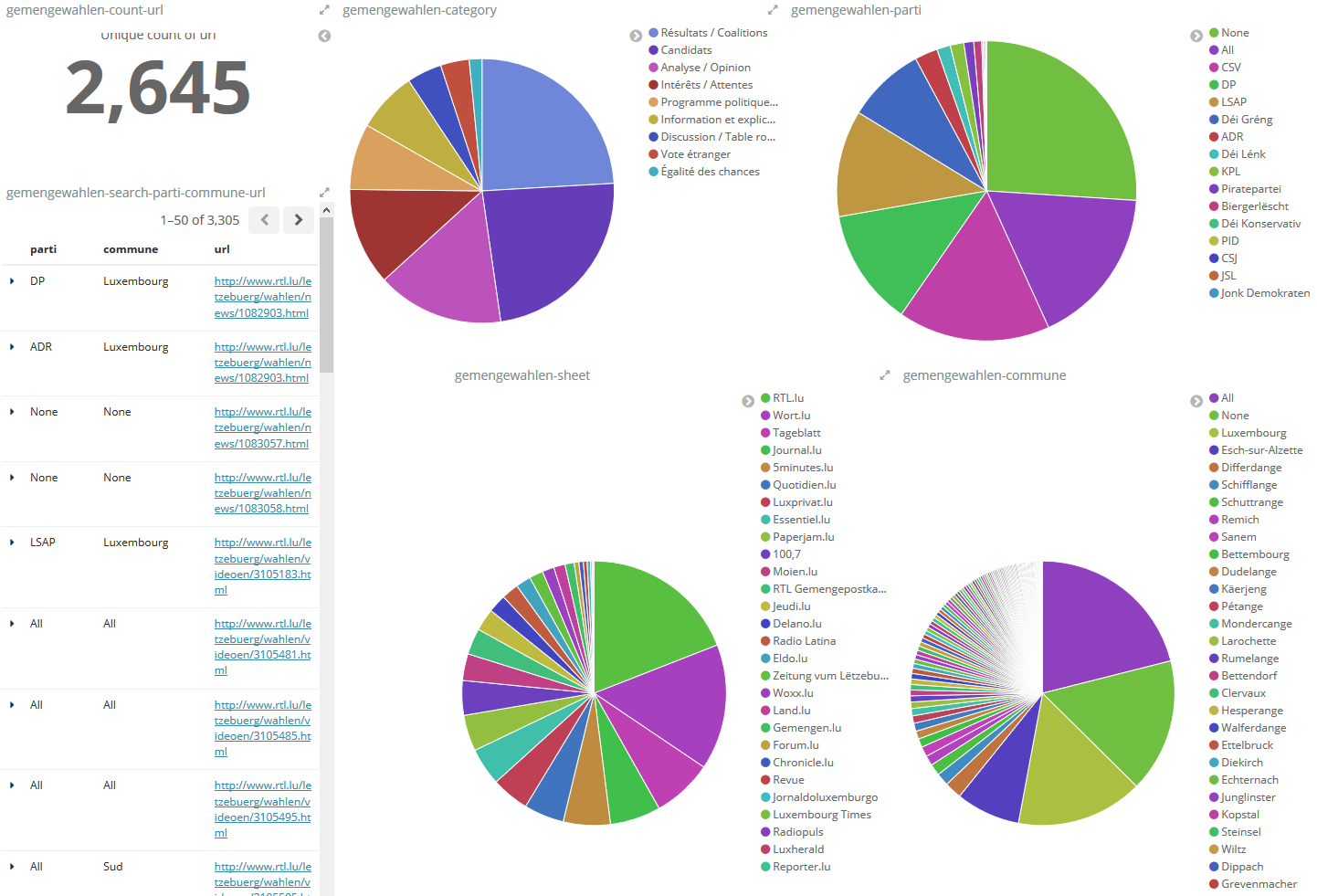
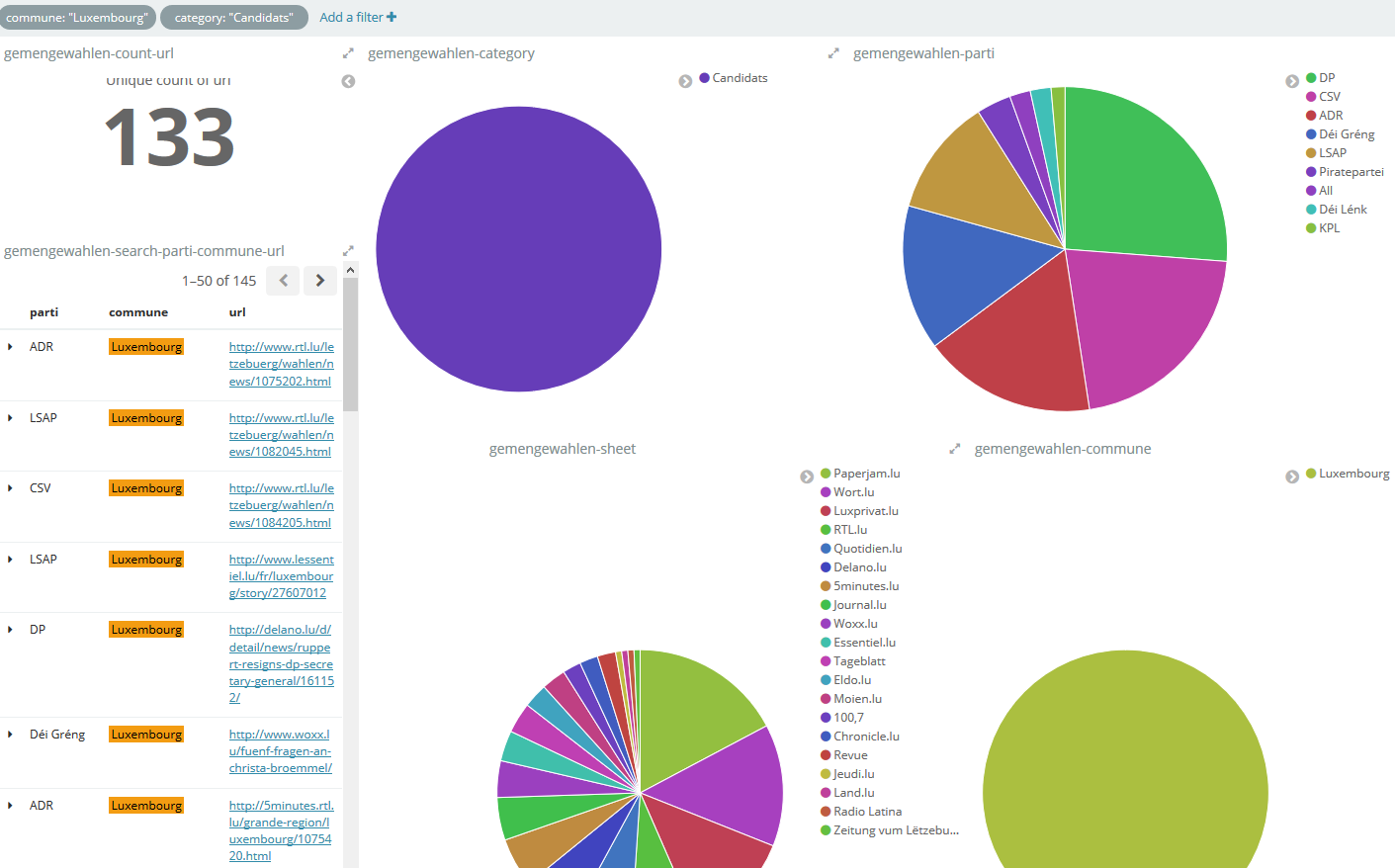
Since this method of processing news articles is very time-consuming, this form of examination might go beyond the goal of collecting and preserving websites and will most likely not be a regular exercise for the Luxembourg Web Archive. The main objective of this project was to present the possibilities and benefits of working with archived web materials, with a relatable subject, in an easily accessible way. Moreover, we are able to share insights about our activities, without accessing the actual web archive.
Want to see more?
If you want to browse the Luxembourg Web Archive and view the archived versions of the sites contained in this collection, we are happy to invite you to the National Library of Luxembourg, where all contents of our web archive are accessible from our working stations and devices connected to the BnL Wifi.
How to get to the BnL