The process
What we collect is more than screenshots or code.
We try to capture every site exactly as it is, in as much depth and detail as possible.
1
A website is crawled by our “robot”
The heretrix webcrawler crawls over every part of a website (which is also how indexing for search engines works).
2
All elements of the site are downloaded
Text, images, documents, layout… everything that is publicly available on the site is downloaded.
3
An exact copy of the site is created
The archival copy of the website can be browsed with all the functionalities of the original.
In time, with every copy of a website, the archive will form a timeline for a website, which can be naviguated via our Wayback Machine.

Websites, Domains and Hosts
When we talk about archiving websites, it is important to know that the Luxembourg Web Archive mainly uses lists of domains to build collections.
However, there can be additional hostnames added to a domain, forming hosts, which are actually what we commonly mean by websites. In the example to the right, bnl.lu and data.bnl.lu are completely different websites under the same domain. Ideally, our crawlers are able to identify all hosts by crawling the domain and archive those as well. The more complete the seed list, the higher the chances that all relevant websites are being captured. If you want to find out more about the terminology of web archiving, visit our dictionary:

Is your website already part of the
Luxembourg Web Archive?
Here is a simple checklist to see whether your website might,
or should be part of the Luxembourg Web Archive.
.LU
Does your website end in “.lu” and is therefore part of a “.lu” Top Level Domain (TLD) ?
What you should do
You’re all set.
All “.lu” domains are being harvested on a regular basis in our broad crawls. Find out more about our harvesting methods below.
Published in Luxembourg
Was your website published in Luxembourg, but in a different Top Level Domain than “.lu” (e.g. “.com”, “.de”, “.eu”…) ?
What you should do
Send it in! Tell us about it! You can call, write an Email or simply fill out the form on our homepage:
ContactLuxembourg citizens
You own a website, or contributed content to a website, or know of a website in relation with Luxembourg and Luxembourg citizens?
Social media?
Is the website you are concerned about part of a social media platform, such as a Facebook page, an Instagram profile or a Twitter Account?
What you should do
We don’t archive social media on a regular basis, nor are we able to harvest large numbers of social media profiles at once.
If you would like to suggest a relevant social media page to be included in the Web Archive, we still encourage you to do so, even though in most cases we won’t be able to capture any content from these websites for now.
Collection Policy
Find out more detailed information about what is being preserved in the Luxembourg Web Archive.
Collection PolicyPossibilities and Limits
Web archives are valuable sources of information, but there are limits to what we can achieve and many many reasons, why web archives are not perfect.
FRENCH VERSIONIs your website archive compliant?
GuidelinesWe have our methods
Domain crawls
Domain crawls are operated twice a year and create a snapshot of the all “.lu” addresses plus additional lists of websites determined by the Luxembourg Web Archive.
These crawls cover a large number of websites at once, but can be tardy in capturing sites that are changing at a rapid pace or may have disappeared between two harvests.
Event collections
Event collections try to harvest as much information as possible about a certain event over a limited time frame.
The seed lists for event crawls are restrictive, but the frequency of captures will likely be higher.
There is always a start and end date to event crawls, which could be determined in advance, (e.g. for elections), or could depend on the urgency of surprising events (e.g. natural catastrophes or Covid-19).
Thematic collections
Thematic collections cover a specific topic or field of interest, with a higher priority to the Luxembourg Web Archive. This could be linked to the pace of changing information, or the importance of the topic. The seed lists will expand over time and have additional harvests, complementing the coverage by domain crawls and event collections.
Different collections,
one web archive
The domain crawls form the basis of the web archive. A large number of websites, harvested all at once, creating a “snapshot” of the Luxembourg web at a given moment. However, these crawls take around one month to complete, and we are only able to operate 2 domain crawls per year.
Naturally there are a lot of areas on the web, where we miss out on changes in between domain crawls. In order to complete the picture formed by the large scale crawls, we are also implementing thematic collections: concentrating on types of websites and topics which warrant more attention and more frequent captures.
There is always some kind of buzz on the web. Topics and events occupy the flow of new information and mark a specific moment in Internet history. These events are captured in event collections, adding to the domain crawls and thematic collections. With different methods and different collections, all captures of all websites are integrated into the same web archive.

Information for webmasters
The Luxembourg Web Archive harvests websites automatically in accordance with the law of the 25th of June 2004 “portant réorganisation des instituts culturels de l’Etat” and the “Règlement grand-ducal du 6 novembre 2009 relatif au dépôt légal”. Publications in non-material forms which are accessible to the public through electronic means, for instance through the Internet, are subject to legal deposit in Luxembourg.
The websites that are harvested through these means enrich the patrimonial collections of the National library of Luxembourg which can thus collect and preserve the digital publications for future generations.
How does it work?
The harvesting is done using the Heretrix webspider.
This program doesn’t interpret Javascript completely and hence it can happen that it generates some false URLs.
This is of course not the intention of the Luxembourg Web Archive but can unfortunately not be avoided at this stage of the technology.
robots.txt
The spider of the Luxembourg Web Archive respects the robots.txt file with a few exceptions. Any file necessary for a complete display of a webpage (e.g. css, images, …) is downloaded even if it is in the robots.txt exclusion list. Moreover all landing pages for all sites are collected regardless of the robots.txt settings. In any event, the BnL reserves the right to change this policy as needed, in accordance with the “Règlement grand-ducal du 6 novembre 2009 relatif au dépôt légal”.
Collection policy
Every collection, resulting from domain crawls, event or thematic collections is defined by our collection policy.
The different policy components, such as the frame, objectives and contents of the collection, are explained in the following categories.
Collection proposal
Intent
What is the topic, occasion or motivation behind the creation of the collection.
Scope
How broad or narrow is the field of interest for this topic and what is the time frame for harvests.
Strenghts and areas of interest
Different types of websites imply different challenges in capturing their contents. This means that there are necessarily limits to the completeness of coverage in terms of number of seeds, and changes on websites. The indication of selective, extensive, comprehensive or broad coverage on different parts of a collection, helps in understanding the limitations and priorities of the project.
Harvest strategy
Seed list
Which seeds are used to build the collection. Which types of websites are included.
Frequency of captures
The number of times, different types of seeds should be captured.
Collection size
Volume of data and number of documents to be captured.
Document types
The types of documents to be found in the collection and possible exclusions
Criteria for foreign websites
Does the topic warrant the inclusion of websites outside of the .lu domain?
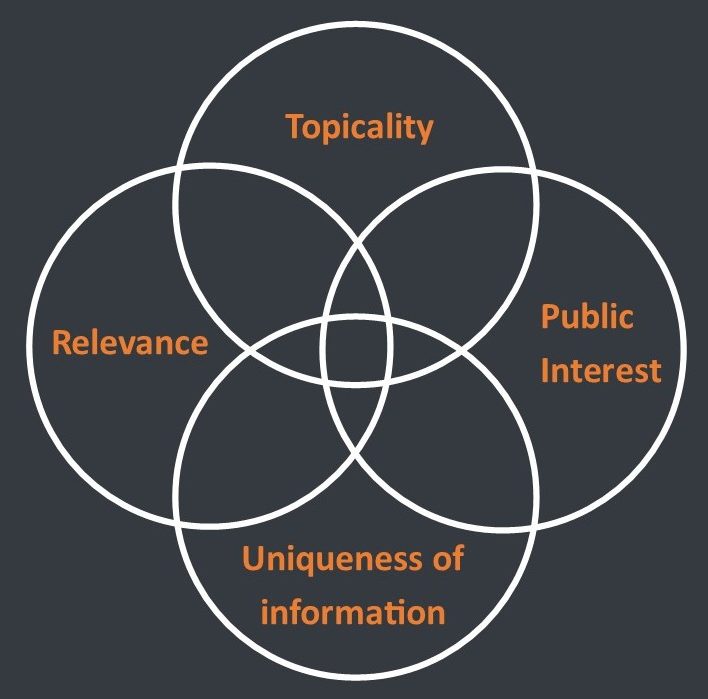
How we collect
Based on the experience of event collections from 2017 to 2020 we are able to illustrate the selection criteria that shape our special collections.
Selection criteria
We need to make sure to look in the right places to select the right elements for each collection. This means, to determine whether a seed should be included in the seed list. The criteria we set up will help web archive users in following the structure and reasoning behind our special collections. Furthermore, a consistent policy helps with the organisation and search for additional seeds throughout the project.
Topicality:
Is this about the topic in question?
Does the website show information about politics, music, science or whatever the topic of the collection is?
Relevance:
Is this important?
How relevant and important is the website’s content to the topic and how likely is there going to be more interesting information at a later point in time? This is important in determining the depth of the harvest, because not the whole website might be relevant to the topic. It can be difficult to determine how relevant a seed is going to be, so the general approach is to be more inclusive than too selective.
Public interest:
Should people know about this?
This question plays a role in drawing certain lines: for instance, “private” profiles of political candidates on social media, which would not represent them in their function of politicians, would not be included because they only concern their private lives and are therefore not relevant to the topic of politics. These profiles might be publicly visible on social networks, but are clearly not meant to be interpreted in the political context.
Uniqueness of information:
Haven’t I seen this somewhere else?
An important factor in determining the urgency and frequency of collecting websites. Even though the websites of political parties are an essential part of the collection, their content could be rather static and only be updated at rare intervals during the election campaign. Moreover, their content is repeated many times over in press conferences, posters, flyers etc. The more unique information, found for example in personal blogs, video channels, comments, and discussions on social media, would also be more likely to have a shorter life-span on the web, making some of these examples the most difficult to harvest. If there are no major objections in respect to any of these criteria, a website can be added as a seed, which will help in systematically looking for similar websites. Furthermore, this examination gives a first idea on the next step of the archiving process.
Archiving social media
Social media arguably represent some of the most unique content on the web, with no comparable counterpart in print media. For instance, in the context of politics, the campaign information from political party websites, is for the most part also published in brochures, flyers and posters. Social media allow for politicians to have more individual platforms and most importantly, exchanges with the public, other politicians, journalists, etc. Social media are also the most volatile source of information, since new content appears and disappears very quickly. For a number of technical and budgetary reasons, social media are the most difficult websites to capture content from.
Costly and often unreliable – Facebook crawls show to produce results of varying quality, due to Facebook’s active efforts of preventing the archival of pages and profiles.
In many cases we can only include Facbook seeds to show that they are part of the collection, but we are far from being able to expect a sense of completeness in coverage
Less costly and more reliable than Facebook, Twitter crawls produce better results and are mostly limited by time constraints for harvests, since we might still miss information with daily crawls.
Twitter also follows a different policy regarding web archiving, where it is actually encouraged and several methods are made available for that purpose.
Youtube
Video files are generally heavier and take up more space compared to other types of media. Therefore Youtube pages can be costly to harvest.
Similar to Facebook, capturing Instagram profiles is difficult and we don’t have the resources or technical means to significantly improve this situation.
Restrictions
While the Luxembourg Web Archive strives to grow over time and expand its inventory of the Luxembourg web space, there are exceptions to this inclusive approach:
– Websites will not be harvested, or only partially harvested, if the technical resources necessary for its archival are not justified by, or out of proportion to its relation to the Luxembourg legal deposit.
– No information will be permanently deleted from the Luxembourg Web Archive. In case of a court decision on the illegality of certain contents, the BnL may have to withdraw access to this content from the browsable web archive.
– Exclusions due to reasons of privacy concerns are generally not applicable. The right to be forgotten is not absolute and does not supersede the right to public information.
– The LWA is not required to ask for permission to harvest and archive websites within the legal deposit. The transparency about interactions with websites is nonetheless important and should be consistent with the LWA’s strategy in relation to the inclusion or exclusion of websites from the archive. During archiving operations, the LWA communicates a URL to website owners, which explains the legal deposit procedure (http://crawl.bnl.lu).